Bitplane Image Coding with Parallel Coefficient Processing for High Throughput Compression with GPUs

|
|
Bitplane Image Coding with Parallel Coefficient Processing for High Throughput Compression with GPUs |
|
|
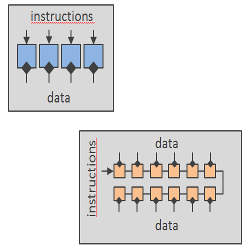
For more than 30 years, the throughput of microprocessors was mainly escalated by means of increasing their clock frequency. In 2005, the clock frequency hit a wall at approximately 4 GHz. The microchip industry then changed its strategy and began producing microprocessors with multi-thread capabilities. Nowadays, the Graphics Processing Units (GPUs) are the microprocessors that provide the highest computational throughput and lowest power consumption. They are based on the Single Instruction, Multiple Data (SIMD) principle, executing the same instruction to multiple data. Unfortunately, current compression schemes can not achieve high performance in GPUs because their core algorithms were devised for single-thread processors. This line of work proposes an end-to-end wavelet-based image/video codec tailored for SIMD-based architectures. The first paper below presents an implementation of the wavelet transform (the first coding stage of the codec) that employs the latest techniques introduced in Nvidia GPUs. The second and third papers introduce and implement in a GPU a new bitplane coding scheme (the core coding stage of the codec) that allows fine-grain parallelism. The fourth paper describes the implementation of the end-to-end image/video codec and evaluates its performance. The last paper introduces a variation to the bitplane coding engine to allow the codec regulate its computational complexity (or encoding time). Experimental results indicate that the proposed codec is 30x faster and consumes 40x less power than the fastest implementations of current compression standards. |
| IMPLEMENTATION OF THE DWT IN A GPU THROUGH A REGISTER-BASED STRATEGY |
|
ABSTRACT: The release of the CUDA Kepler architecture in March 2012 has provided Nvidia GPUs with a larger register memory space and instructions for the communication of registers among threads. This facilitates a new programming strategy that utilizes registers for data sharing and reusing in detriment of the shared memory. Such a programming strategy can significantly improve the performance of applications that reuse data heavily. This paper presents a register-based implementation of the Discrete Wavelet Transform (DWT), the prevailing data decorrelation technique in the field of image coding. Experimental results indicate that the proposed method is, at least, four times faster than the best GPU implementation of the DWT found in the literature. Furthermore, theoretical analysis coincide with experimental tests in proving that the execution times achieved by the proposed implementation are close to the GPU's performance limits. |
| PAPER: P. Enfedaque, F. Auli-Llinas, and J. C. Moure, Implementation of the DWT in a GPU through a register-based strategy, IEEE Trans. Parallel Distrib. Syst., vol. 26, no. 12, pp. 3394-3406, Dec. 2015. (DOI:10.1109/TPDS.2014.2384047, doc.pdf740K) |
| IMPLEMENTATION (by Pablo Enfedaque): here |
| BITPLANE IMAGE CODING WITH PARALLEL COEFFICIENT PROCESSING |
|
ABSTRACT: Image coding systems have been traditionally tailored for Multiple Instruction, Multiple Data (MIMD) computing. In general, they partition the (transformed) image in codeblocks that can be coded in the cores of MIMD-based processors. Each core executes a sequential flow of instructions to process the coefficients in the codeblock, independently and asynchronously from the others cores. Bitplane coding is a common strategy to code such data. Most of its mechanisms require sequential processing of the coefficients. The last years have seen the upraising of processing accelerators with enhanced computational performance and power efficiency whose architecture is mainly based on the Single Instruction, Multiple Data (SIMD) principle. SIMD computing refers to the execution of the same instruction to multiple data in a lockstep synchronous way. Unfortunately, current bitplane coding strategies can not fully profit from such processors due to inherently sequential coding task. This paper presents bitplane image coding with parallel coefficient processing (BPC-PaCo), a coding method that can process many coefficients within a codeblock in parallel and synchronously. To this end, the scanning order, the context formation, the probability model, and the arithmetic coder of the coding engine have been re-formulated. Experimental results suggest that the penalization in coding performance of BPC-PaCo with respect to traditional strategies is almost negligible. |
| PAPER: F. Auli-Llinas, P. Enfedaque, J. C. Moure, and V. Sanchez, Bitplane image coding with parallel coefficient processing, IEEE Trans. Image Process., vol. 25, no. 1, pp. 209-219, Jan. 2016. (DOI:10.1109/TIP.2015.2484069, doc.pdf625K) |
|
PRESENTATION (short): slides.pptx35M PRESENTATION (long): slides.pptx35M |
| GPU IMPLEMENTATION OF BITPLANE CODING WITH PARALLEL COEFFICIENT PROCESSING FOR HIGH PERFORMANCE IMAGE COMPRESSION |
|
ABSTRACT: The fast compression of images is a requisite in many applications like TV production, teleconferencing, or digital cinema. Many of the algorithms employed in current image compression standards are inherently sequential. High performance implementations of such algorithms often require specialized hardware like field integrated gate arrays. Graphics Processing Units (GPUs) do not commonly achieve high performance on these algorithms because they do not exhibit fine-grain parallelism. Our previous work introduced a new core algorithm for wavelet-based image coding systems. It is tailored for massive parallel architectures. It is called bitplane coding with parallel coefficient processing (BPC-PaCo). This paper introduces the first high performance, GPU-based implementation of BPC-PaCo. A detailed analysis of the algorithm aids its implementation in the GPU. The main insights behind the proposed codec are an efficient thread-to-data mapping, a smart memory management, and the use of efficient cooperation mechanisms to enable inter-thread communication. Experimental results indicate that the proposed implementation matches the requirements for high resolution (4K) digital cinema in real time, yielding speedups of 30x with respect to the fastest implementations of current compression standards. Also, a power consumption evaluation shows that our implementation consumes 40x less energy for equivalent performance than state-of-the-art methods. |
| PAPER: P. Enfedaque, F. Auli-Llinas, and J. C. Moure, GPU implementation of bitplane coding with parallel coefficient processing for high performance image compression, IEEE Trans. Parallel Distrib. Syst., vol. 28, no. 8, pp. 2272-2284, Aug. 2017. (DOI:10.1109/TPDS.2017.2657506, doc.pdf322K) |
| IMPLEMENTATION (by Pablo Enfedaque): here |
| GPU-ORIENTED ARCHITECTURE FOR AN END-TO-END IMAGE/VIDEO CODEC BASED ON JPEG2000 |
|
ABSTRACT: Modern image and video compression standards employ computationally intensive algorithms that provide advanced features to the coding system. Current standards often need to be implemented in hardware or using expensive solutions to meet the real-time requirements of some environments. Contrarily to this trend, this paper proposes an end-to-end codec architecture running on inexpensive Graphics Processing Units (GPUs) that is based on, though not compatible with, the JPEG2000 international standard for image and video compression. When executed in a commodity Nvidia GPU, it achieves real time processing of 12K video. The proposed S/W architecture utilizes four CUDA kernels that minimize memory transfers, use registers instead of shared memory, and employ a double-buffer strategy to optimize the streaming of data. The analysis of throughput indicates that the proposed codec yields results at least 10× superior on average to those achieved with JPEG2000 implementations devised for CPUs, and approximately 4× superior to those achieved with hardwired solutions of the HEVC/H.265 video compression standard. |
| PAPER: C. de Cea-Dominguez, J. C. Moure, J. Bartrina-Rapesta, and F. Auli-Llinas, GPU-oriented architecture for an end-to-end image/video codec based on JPEG2000, IEEE Access, vol. 8, pp. 68474-68487, Dec. 2020. (DOI:10.1109/ACCESS.2020.2985859, doc.pdf393K) |
| IMPLEMENTATION (by Carlos de Cea): here |
| COMPLEXITY SCALABLE BITPLANE IMAGE CODING WITH PARALLEL COEFFICIENT PROCESSING |
|
ABSTRACT: Very fast image and video codecs are a pursued goal both in the academia and the industry. This paper presents a complexity scalable and parallel bitplane coding engine for wavelet-based image codecs. The proposed method processes the coefficients in parallel, suiting hardware architectures based on vector instructions. Our previous work is extended with a mechanism that provides complexity scalability to the system. Such a feature allows the coder to regulate the throughput achieved at the expense of slightly penalizing compression efficiency. Experimental results suggests that, when using the fastest speed, the method almost doubles the throughput of our previous engine while penalizing compression efficiency by about 10%. |
| PAPER: C. de Cea-Dominguez, J. C. Moure, J. Bartrina-Rapesta, and F. Auli-Llinas, Complexity scalable bitplane image coding with parallel coefficient processing, IEEE Signal Process. Lett., vol. 27, pp. 840-844, Dec. 2020. (DOI:10.1109/LSP.2020.2990307, doc.pdf348K) |
| REAL-TIME 16K VIDEO CODING ON A GPU WITH COMPLEXITY SCALABLE BPC-PACO |
|
ABSTRACT:The advent of new technologies such as high dynamic range or 8K screens has enhanced the quality of digital images but it has also increased the codecs’ computational demands to process such data. This paper presents a video codec that, while providing the same coding features and performance as those of JPEG2000, can process 16K video in real time using a consumer-grade GPU. This high throughput is achieved with a technique that introduces complexity scalability to a bitplane coding engine, which is the most computationally complex stage of the coding pipeline. The resulting codec can trade throughput for coding performance depending on the user’s needs. Experimental results suggest that our method can double the throughput achieved by CPU implementations of the recently approved High-Throughput JPEG2000 and by hardwired implementations of HEVC in a GPU. |
| PAPER: C. de Cea-Dominguez, J. C. Moure, J. Bartrina-Rapesta, and F. Auli-Llinas, Real-time 16K video coding on a GPU with complexity scalable BPC-PaCo, ELSEVIER Signal Processing: Image Communication, vol. 99, pp. 1-10, Nov. 2021. (DOI:10.1016/j.image.2021.116503, doc.pdf437K) |
| IMPLEMENTATION (by Carlos de Cea): here |
| ACCELERATING BPC-PACO THROUGH VISUALLY LOSSLESS TECHNIQUES |
|
ABSTRACT:Fast image codecs are a current need in applications that deal with large amounts of images. Graphics Processing Units (GPUs) are suitable processors to speed up most kinds of algorithms, especially when they allow fine-grain parallelism. Bitplane Coding with Parallel Coefficient processing (BPC-PaCo) is a recently proposed algorithm for the core stage of wavelet-based image codecs tailored for the highly parallel architectures of GPUs. This algorithm provides complexity scalability to allow faster execution at the expense of coding efficiency. Its main drawback is that the speedup and loss in image quality is controlled only roughly, resulting in visible distortion at low and medium rates. This paper addresses this issue by integrating techniques of visually lossless coding into BPC-PaCo. The resulting method minimizes the visual distortion introduced in the compressed file, obtaining higher-quality images to a human observer. Experimental results also indicate 12\% speedups with respect to BPC-PaCo. |
| PAPER: F. Auli-Llinas, C. de Cea-Dominguez, and M. Hernandez-Cabronero, Accelerating BPC-PaCo through visually lossless techniques, ELSEVIER Journal of Visual Communication and Image Representation, vol. 89, p. 103672, Nov. 2022. (DOI:10.1016/j.jvcir.2022.103672, doc.pdf258K) |
| PROBABILITY MODELS FOR HIGHLY PARALLEL IMAGE CODING ARCHITECTURE |
|
ABSTRACT:A key aspect of image coding systems is the probability model employed to code the data. The more precise the probability estimates inferred by the model, the higher the coding efficiency achieved. In general, probability models adjust the estimates after coding every new symbol. The main difficulty to apply such a strategy to a highly parallel coding engine is that many symbols are coded simultaneously, so the probability adaptation requires a different approach. The strategy employed in previous works utilizes stationary estimates collected a priori from a training set. Its main drawback is that statistics are dependent of the image type, so different images require different training sets. This work introduces two probability models for a highly parallel architecture that, similarly to conventional systems, adapt probabilities while coding data. One of the proposed models estimates probabilities through a finite state machine, while the other employs the statistics of already coded symbols via a sliding window. Experimental results indicate that the latter approach improves the performance achieved by the other models, including that of JPEG2000 and High Throughput JPEG2000, at medium and high rates with only a slight increase in computational complexity. |
| PAPER: F. Auli-Llinas, J. Bartrina-Rapesta, and M. Hernandez-Cabronero, Probability models for highly parallel image coding architecture, ELSEVIER Signal Processing: Image Communication, vol. 112, p. 116914, Mar. 2023. (DOI:10.1016/j.image.2022.116914, doc.pdf433K) |